
Storage
Arcfra Block Storage
ABS is AECP’s innovative distributed block storage component, with high performance and availability battle-tested in production.
Maximize Application Efficiency
Achieve peak performance with optimized full-stack solutions, delivering high-speed, low-latency operations that keep your applications running smoothly and efficiently.
Keep Business Uninterrupted
Leverage proven reliability and stability to maintain seamless services, avoiding costly downtimes and ensuring continuous operation.
Optimize Costs and Resources
Streamline resource management with a unified storage pool and scalable expansion, enhancing resource utilization while reducing operational costs to meet your business demands effectively.
How is it works
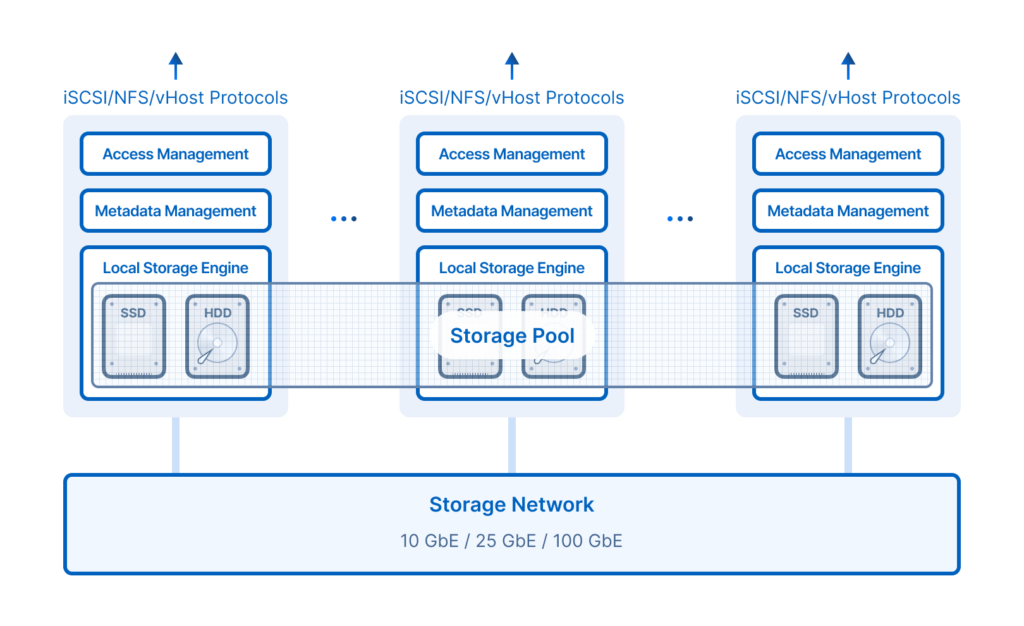
Effortlessly Ensure High Availability with Rich Functions
Data Block Checksum at Hard Disk Level
Deal with silent data corruption through data checksum.
Data Protection at Node Level and Automatic Data Recovery
Data protection is performed among nodes through a multi-replica mechanism; when a component or a node fails, the available space is automatically used, and concurrent data recovery starts among multiple nodes, ensuring that the data redundancy satisfies the expectations at all times.
Protection at Rack Level
Through rack topology configuration, the replicas are automatically placed on different racks to prevent the cluster from being inaccessible caused by power outage or failure of a single rack, further improving the storage reliability.
Snapshot Protection
By generating a snapshot for the storage, the data can be quickly restored to the state at the time when the snapshot was taken, ensuring data security.
Cross-Site Active-Active Clustering
Along with high availability configuration at the client, the stretched active-active cluster guarantees zero RPO and near-zero RTO, providing application availability during disasters.
Intelligent Recovery Policy of Business-First
On the premise of ensuring business I/O, adaptively adjust the speed of recovery or migration according to the system load.
Agile Recovery Mechanism
During node upgrade or maintenance, the expected loss of replicas will not trigger data recovery, and the write requests during the offline period of the replicas will complete data recovery with a smaller granularity after the node is restored.
Abnormal Disk Detection and Isolation
Automatically detects and isolates unhealthy, failing, or low-life disks to reduce the impact on system performance, operations, and maintenance.
Network Fail-Slow Detection and Isolation
Automatically and regularly checks storage and access networks and immediately isolates abnormal nodes and NICs to reduce the impact on system performance.
Elevate Performance Levels with Full Optimization
Fully Distributed Architecture
The distributed architecture eliminates controller bottlenecks, and the concurrent performance increases linearly with the number of nodes.
Proprietary File System Based on Bare Metal Devices
A file system is directly built on bare devices, more suitable for accessing high-performance block storage, avoiding the overhead of the existing Linux file system.
All-Flash Support
Support all-flash storage environments to fully meet enterprises’ needs for high-performance scenarios.
Automatic Tiering of Hot and Cold Data
Cold data automatically sinks to HDD, and hot data remains in the cache layer, fully using SSD hardware’s advantages and further improving performance.
Volume Pinning
Prevent performance degradation caused by cache breakdown by storing storage volume data in the cache layer, ensuring a consistent high performance.
High-Performance I/O Link
When Boost mode is enabled on the cluster, the vhost protocol shares memory between Guest OS, QEMU, and ABS to optimize I/O request processing and data transfer, improving VM performance and reducing I/O latency.
High-Performance Data Transmission
The data is exchanged between cluster nodes through the RDMA protocol, effectively increasing the cluster throughput and reducing the latency.
Seamlessly Scale on Demand
Powerful Expansion Capability
Starting with a small scale, the capacity and performance can be easily expanded online in a single storage pool.
Intelligent Data Migration
Dynamically balance the data distribution within the cluster, and quickly restore the balance of data distribution after storage capacity expansion.
Intelligent Replica Provision
According to the load status of the cluster capacity, the replicas are dynamically adjusted according to the principles of local-first, topological security, localized provision, and capacity balance, to achieve a balance of high performance and high reliability.